The beginning
In 2009 I got my first full-time job working for the Norwegian University of Science and Technology, where I had previously studied and worked part time. This new position was at the Multimedia Centre, a branch of academic and student services. We produced a high quantity of video content, both traditional lectures and shorter educational videos produced in a studio environment. The technical workflow to publish these videos was dependent on manual work. When we wanted to publish video content to iTunesU, we had to manually create rss-feeds. This was done locally on workstation macs with the help of a proprietary app when I began work at the office, but because I had some prior knowledge of PHP, HTML and CSS coding, I decided it would be better to create a simple website on the university network that could help us to publish content more efficiently and with fewer metadata errors. While working at the Multimedia Centre, I noticed a PHP textbook on the office bookshelf. I don’t know why it was there but if it wasn’t for that book, I wouldn’t be a full-time web developer today. The new php web-based tool would improve upon two issues: the inaccuracy of the manual input of metadata and the errors caused by the assignment of video source files.
The feeds that iTunes depended on for content in 2009 generally worked like this: one rss-file per series per quality (SD/HD video). The way the new tool I created worked was that the parent information for the series of videos (usually some basic information for the course), the author of the content, information about the university, and album art would be stored separately from the video episodes. This created a basic one->hasMany relationship. As new content or episodes were added, generic information that applied to all episodes was added automatically from the parent series (course-code, author etc) and titles, description and other metadata could be modified as needed through a web-interface. New rss-files for iTunes were generated as episodes were added. These refreshed once per day, but if we wanted to add content sooner could log into the iTunesU admin interface and trigger a manual refresh. The metadata was stored on the university MySQL server, and the video files were rendered by two Xservers from Apple that were managed by us. They ran in a Xgrid cluster using Podcast Producer, which proved to be incredibly unreliable. Shortly after we had this workflow in production Apple stopped further development and support for Xserve, Xgrid and Podcast Producer.
openVideo is born
With varied success and a quite a few issues with the current workflow setup for video rendering we had to think of some alternatives. The solution was Episode from Telestream, a video render app that ran in osx with built in cluster rendering support. I quickly assembled some batch scripts (also in PHP) that shared the same basic level classes with the web tool that managed the video podcasts. These scripts made a watch-folder based workflow, where everyone in the office could drop a video file into a shared upload folder (thanks to AFP in the osx server, we all used macs) and the render-batch-script logic would run every 5 minutes, looking for new uploads and video files that were finished rendering. At this time (the summer of 2011) I had a database with all metadata, and an automatic render flow. I thought I may as well try to make a simple experimental video content webpage based on all the information in the video files that we already had. With the help of the same basic php core classes and functions that were already made, I created a simple video front-end. Within a year, it had become popular with the students at the university, who favored streaming their lecture videos over downloading them as podcasts. This meant that the students no longer had to download iTunes and accept their EULA. During the summer of 2012, I rewrote the system into three modules:
- autoRender: A CLI based video render and file workflow handler.
- openVideo Admin: The admin interface for data management.
- openVideo: The front-end video content site.
These modules share access to the same filesystem and DB. At this point I had the sole responsibility for the development and maintenance of the entire system. It was an unique opportunity for me to delve into every aspect of web development, like DB-structure planning, back/front-end coding, UI, video rendering and optimizing, and user feedback. Rapid prototyping and continuous deployment created a constant improvement approach. Students became testers for new functionality, and as a one-man operation that was ideal. As this was considered an added service to students (no cost or fees involved), most users were also very patient and forgiving when it came to failures for the sake of progress. A third major update was completed in 2014 with the most effort put in the UI--both on the public user front end and the admin interface.
openVideo is dead
Towards the end of 2014 I was preparing to move to the United States and had to leave my job at the university. The openVideo web and file hosting was moved to the university IT-department. There was no way for the IT-department (or anybody else for that matter) to take control of further development and user support. In hindsight I realize that the system should have taken place in a open source environment. The early versions did not contain what I would consider “great code,” as I was learning on the job, so to speak. The system was also tailored made to our needs, however I am sure there was and possibly still are educational institutions with the exact same challenges. I would have loved for openVideo to be a open source platform, ideally with a higher education community with development and support from multiple institutions. Maybe next time...
I am not sure about the fate of NTNU openVideo at the moment. The last I heard they were moving content to a commercial platform. System is still accessible here: http://video.adm.ntnu.no
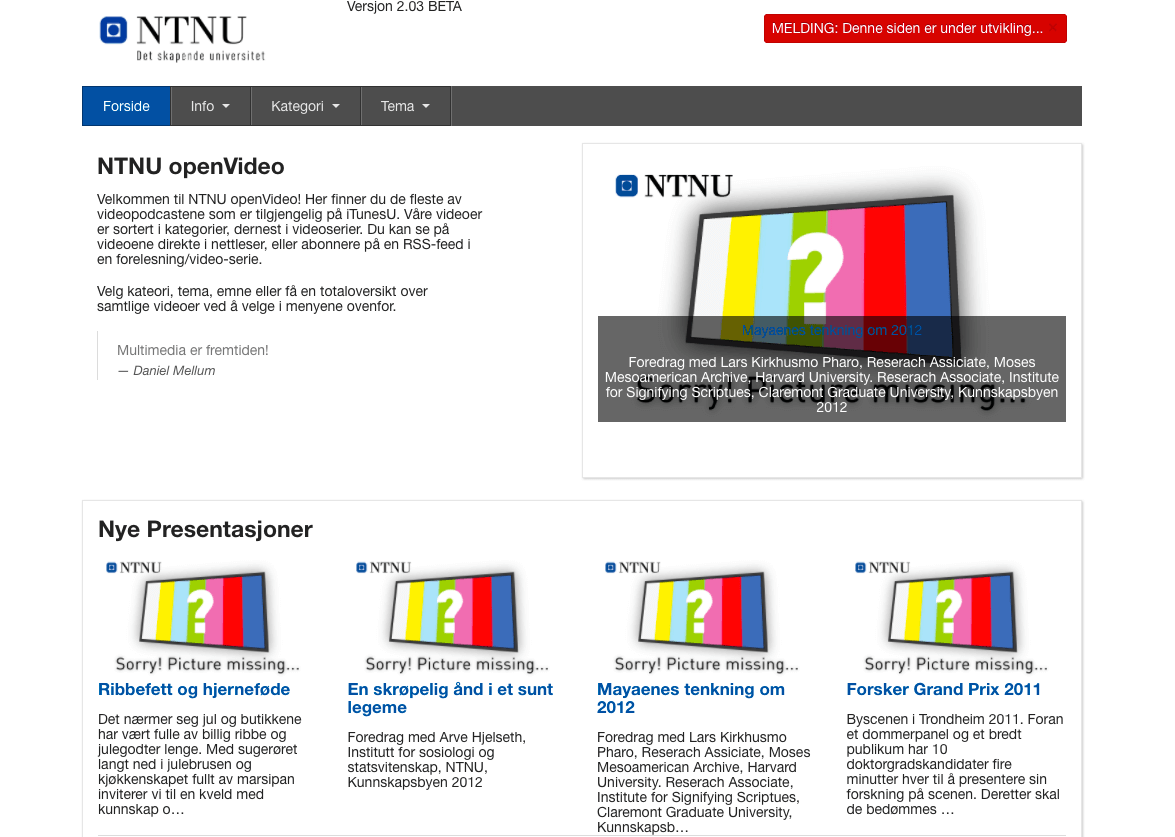
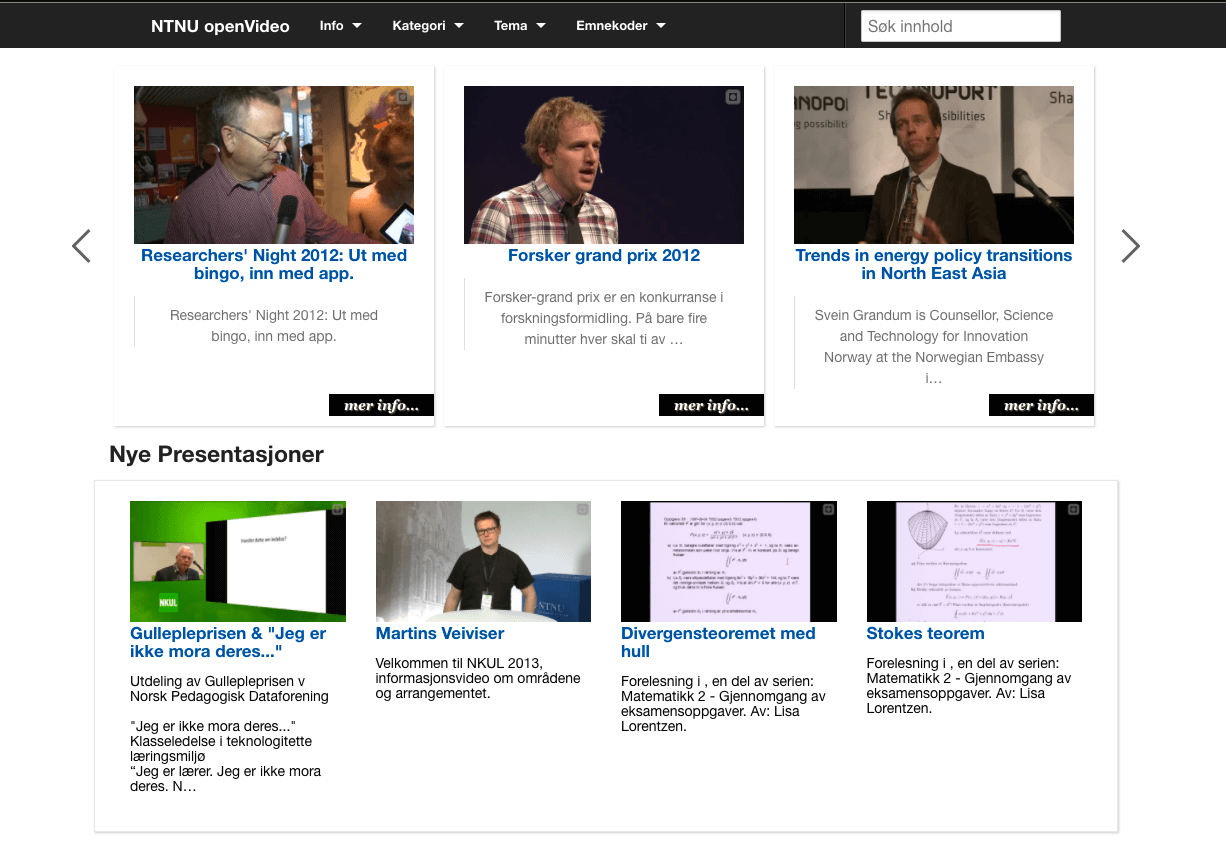
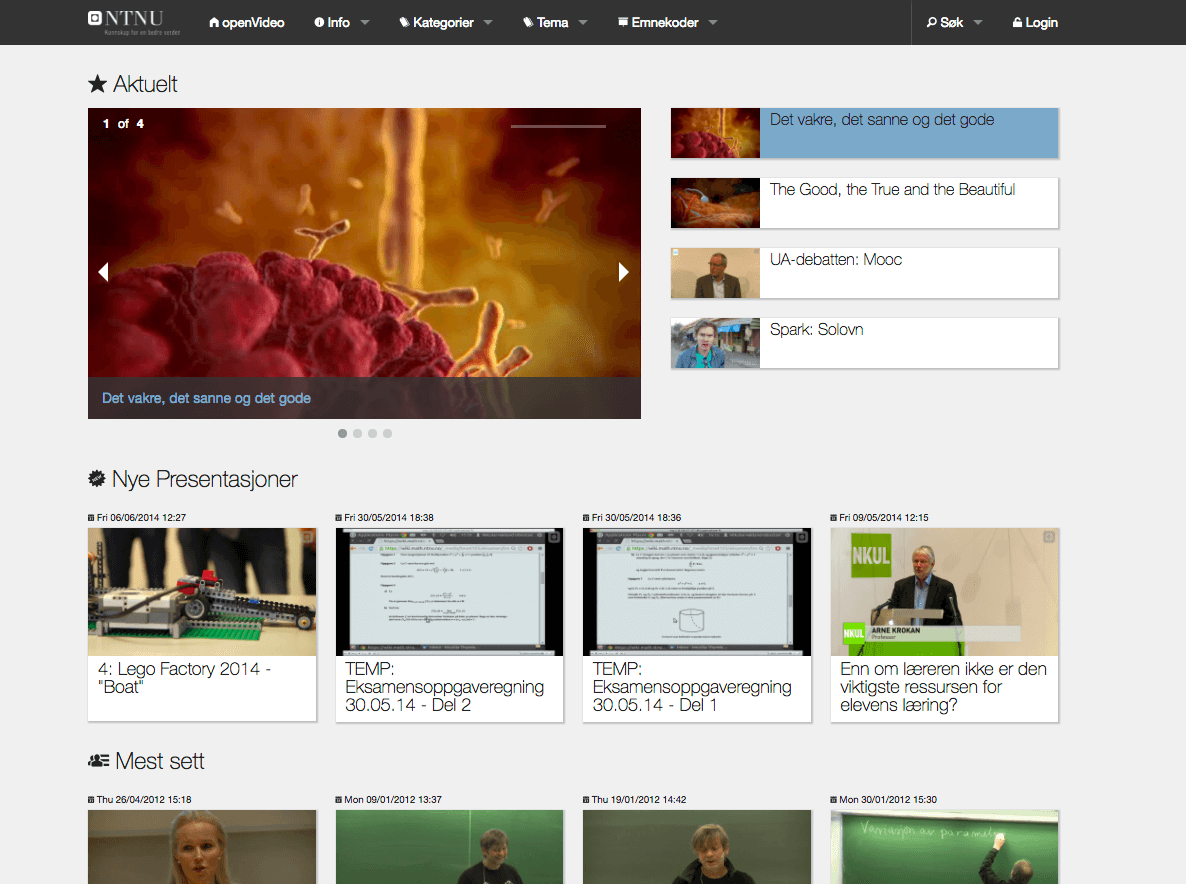
From left to right: NTNU openVideo in 2012, 2014 and 2015.
Images extracted from the Wayback Machine
Share this by url